
NumPy は、Python でのベクトル・行列計算をスムーズにしてくれるモジュールの1つです。
計算だけでなく、データ加工をサクッと素早くできる、といったメリットもあります。
データ分析や人工知能などで活用必須のライブラリです。
NumPyの文法を活用すると、
- 処理をサクッと実装できる
というメリットがあります。
その反面、他の方の書いたサンプルコードを理解するときに、
- (Python以外のNumPy用の)文法を知らないと理解できない
といったデメリットがあります。
NumPyは、行列などを扱うことが多いので、
多次元の配列に慣れてない方は最初はハードルが高いかもしれません。
そういった場合には、様々なサンプルコードを動かすのがおすすめです。
サンプルに入力する初期値をいろいろ変えて出力結果を見る(動作確認する)ことで、
学びたいアルゴリズムを理解しやすくなります。
NumPy配列の初期値を変えるのには、
様々な配列生成の方法(初期化)を知っておくのが役立ちます。
そこで本シリーズでは、NumPyの配列生成や初期化について、まとめています。
第1弾の記事では、「ゼロ行列」の生成方法について、サクッとわかりやすくまとめました↓
続く第2弾では、「イチ行列」の生成方法について解説しています↓
さらに第3弾では、「単位行列」の生成方法について解説しました↓
『【Python NumPy】ベクトル・行列の生成・初期化方法(3):単位行列の生成( identity、eye)について、サンプルコードとともに、サクッとわかりやすくまとめました【Python 入門】』
第4弾の本記事は、シリーズの第4弾として、第1−3弾と比べて
- 行列を「より高速に生成」する方法
について、サンプルコードとともに、サクッとわかりやすくまとめたいと思います。
大規模なデータや高速計算、大量の配列、配列を繰り返し使う処理などを行いたいあなたにオススメの記事となっています。









【Python NumPy 独学】ベクトル・行列の生成・初期化方法(4):高速な配列の生成方法(empty)について、サンプルコードとともに、サクッとわかりやすくまとめました【Python 入門】
(1), 高速に行列を生成する方法(empty)
1次元配列の生成

まず1次元の配列(ベクトル)を生成してみます。
In[2] のように、np.empty( ) を使います。
かっこの中に、要素の数を指定します。
上のサンプル例では、5この要素の配列を生成するため、かっこの中に5を指定しています。
生成したベクトルを変数 array1 に代入しています。
In[3] のようにすることで、array1 の中身を確認できます。
ここでは要素が 0.0 で生成されています。
これはゼロで初期化されているわけでなく、たまたまゼロが格納されていたメモリ領域を確保した結果です。
次の例を見ると、そのことが確認できます。
2次元配列の生成
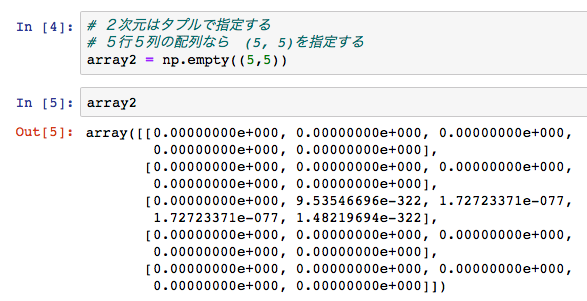
np.emptyメソッドで、2次元の配列(行列)を生成してみます。
In[4] のように、np.empty( ) を使います。
かっこの中には、
- 生成したい行列の行と列の数を書いたタプル
を指定します。
上のサンプル例では、5行5列の要素の配列を生成するため、かっこの中に(5, 5)を指定しています。
生成したベクトルを変数 array2 に代入しています。
In[5] のようにすることで、array2 の中身を確認できます。
array2 の中身は 0.0 だけじゃなく、
1.72723371 e-077 など、
いろいろな値で配列が生成されていることがわかります。
このように、確保したメモリ領域の値がそのまま入っている状態になります。
ちなみに、タプルってなに?という方は以下の記事をどうぞ↓
『【Python 文法 独学】Python の「タプル」とは?タプルの作成、定義、要素、型、削除方法、タプルとリストの違いなど、サクッとまとめました【Python 学習 初心者】』
2次元配列の生成(整数型)
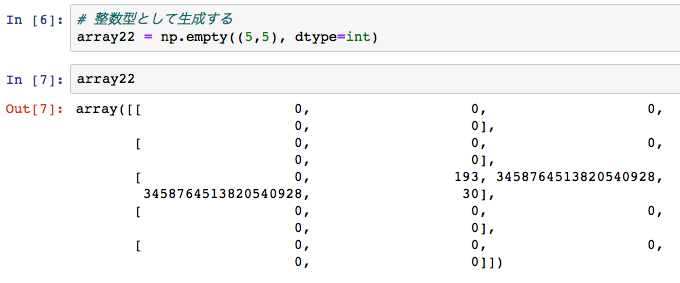
np.emptyメソッドでは、生成するデータの型を指定することができます。
データを整数型に指定したい時には、In [6] のように、
dtype = int
を使います。
書く場所は、生成したい行数と列数のタプルの後に、指定します。
ちなみに dtype は、data type の略で、データ型を表しています。
In [7] のように、配列の中には、整数型の値が入っていることがわかります。
2次元配列の生成(ブール型)
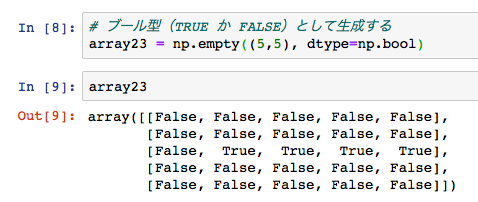
np.emptyメソッドでは、他のデータの型を指定することができます。
データをブール型に指定したい時には、In [8] のように、
dtype = np.bool
を使います。
書く場所は、生成したい行数と列数のタプルの後に、指定します。
In [9] のように、配列の中には、ブール型(True / False)のデータが入っていることがわかります。
2次元配列の生成(複素数型)
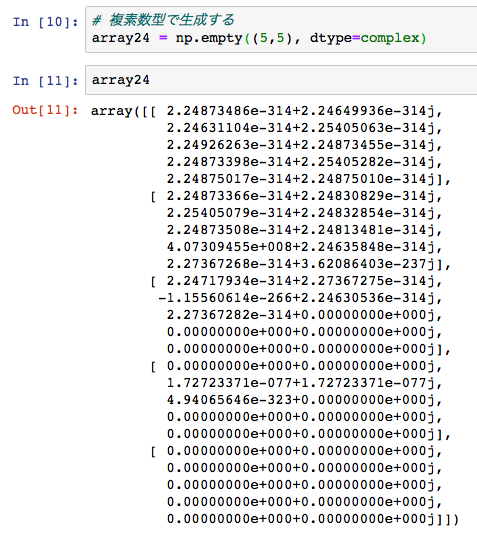
np.emptyメソッドでは、
データを複素数型に指定することもできます。
In [10] のように、
dtype = complex
を使います。
書く場所は、生成したい行数と列数のタプルの後に、指定します。
In [11] のように、配列の中には、複素数型のデータが入っていることがわかります。
複素数の見方ですが、例えば1番上の値
2.24873486e-314 + 2.24649936e-314
では、+の前が実部、+の後ろが虚部になります。
(2), 高速に行列生成できる理由とは?
これまでの行列生成方法(zeros, ones, eye, identityなど)では、値を0や1に初期化した配列を生成するものでした。
(初期化とは、変数に最初から値を入れておくこと、です)
これらの方法では、
- メモリに領域を確保
- 値を0や1にする(初期化)
という2つの手順で配列が生成されます。
- 大規模なデータ
- 数多くの配列
- 高次元の配列
について配列生成する場合には、手順の1と2を両方やることで処理時間がかかってしまいます。
こういった場合には、
処理の2の初期化を行わない配列生成を行うことで、
処理の手間が減ります。
なので、より素早く高速に配列生成を行うことができるわけです。
np.empty( )の活用事例とは?
随時追加していきます。よかったらフォローなどしておくと見逃さないかと思います。
というわけで、本記事では、
ベクトルや行列の生成・初期化のやり方の第4弾として、
- 行列をより高速に生成する方法
について、サンプルコードとともに、サクッとわかりやすくまとめました。
NumPyでは、行列だけでなく、ベクトル(1次元配列)を生成する場面も多くあります。
そこで次の第5話では、
ベクトル(1次元配列)の生成方法の1つ
np. arange
について、わかりやすく、サクッとまとめました↓
こちらもございます↓









「Numpy」については、こちらの書籍でも解説しています(無料)↓

