
「HDF5(エッチディーエフ ファイブ)」は、
階層構造や付属情報のあるデータを、数値データと一緒に格納しておけるデータ形式です。
Hierarchical Data Format version 5 (ヒエラルキカル データ フォーマット バージョン5)の略で、
拡張子が「.h5」や「.hdf5」のファイルになります。
HDF5 は、ディープラーニングなどのデータセットのファイルとしても使われており、
人工知能や機械学習を扱っていきたい場合にも、知っておくと役立つ知識となります。
というわけで、本シリーズでは、
HDF5 について
- HDF5の「データセット(dataset)」
- HDF5 の「グループ(Groups)」
- HDF5 の「アトリビュート(Attribute 属性)」
のプログラミングのやり方について、
サンプルコードを示しながら、サクッとわかりやすく解説したいと思います。
というわけで、本記事では、
HDF5 のデータセットの作成方法について、
Python によるサンプルコードとともにまとめました。












【HDF5 Python】HDF5 とは?HDF形式や、HDF5 をPython から使うための方法などを、サクッと、わかりやすくまとめました【データセット(dataset)作成】
HDF5をPythonから使うには、h5py ライブラリを使う方法があります。
そこでまず、h5py ライブラリをインポートします。
加えて、NumPyも使うので、一緒にインポートしておくと後で便利です。
(0), プログラミングの準備・環境の用意
本記事では、HDF5 をPythonで使うため、
「Anaconda(アナコンダ)」の「Jupiter notebook」 を起動しています。
Anaconda? Jupyter notebookってなに?というあなたや、
- 同じ環境でやりたい
といったあなたは、まず環境構築をされてください。
環境構築のやり方は以下の記事にまとめています↓
『【Python 環境構築】「Anaconda(アナコンダ)」のダウンロードとインストール方法はこちらです(mac編)【anaconda python】』
『【Python 環境構築】Pythonの「ダウンロード(download)」の、わかりやすい、やり方はこちらです(mac編)【Python入門・ 初心者】』
(もちろんあなたのPython 環境でも同様にできるかと思います)
(1), HDF5 をPython から使えるようにする(h5pyライブラリのインポート)
(2), HDF5 ファイルを作成する
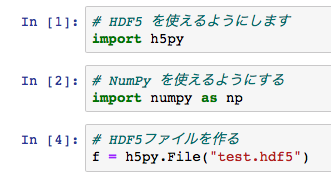
HDF5 ファイルを作成するには、
h5pyのFileメソッドを使います。
作成したいファイルの名前を( ) の中に書きます。
In [4] のように、ファイルはこれから使うので、
「ファイルオブジェクト(ここでは f にしています)」に代入しておきます。
HDF5 のファイル名を決めたら、
次に、HDF5のデータセットの作成してみます。
作成方法の1つ目は、NumPy アレイのデータを代入する方法です。
この先は会員限定になります。
会員の方はログインをお願いいたします。
登録がまだの方は、会員登録をお願いします。
>>> 会員登録はこちら






「Numpy」などについては、こちらの書籍でも解説しています(無料です)↓
「Pandas」については、こちらの書籍でも解説しています(無料です)↓

